안녕하세요. 정글러입니다.
저는 최근에 부스트코스를 잘 활용하고 있는데요,
부스트코스는 SW 온라인 교육 플랫폼으로, 네이버 커넥트재단의 지원 아래에 무료로 양질의 콘텐츠를 제공하고 있습니다.
컴퓨터 과학(Computer Science) / 인공지능(Artificial Intelligence) / 데이터 사이언스(Data Science) / 웹 프로그래밍(Web Programming) / 모바일 프로그래밍(Mobile Programming)
이렇게 총 5가지 분야의 강좌가 준비되어 있는데요,
저 같은 비전공자들이 쉽게 접근할 수 있고, 공부할 수 있어서 넘 좋은 플랫폼인 것 같습니다.
제가 수강하고 있는 수업은 [모두를 위한 파이썬]과 [컴퓨터 비전의 모든 것]인데요,
오늘은 [컴퓨터 비전의 모든 것] 수업을 정리해보고자 합니다.
1. Computer Vision이란?
먼저 그래픽스는 3D 모델의 본질을 가지고 있을 때, 그것을 영상이나 비디오로 만들어내는 기술입니다.
컴퓨터 비전은 반대로 사진이나 비디오의 영상 정보로부터 3D 모델의 본질을 얻어내는 것입니다.
즉, 컴퓨터 비전은 그래픽스의 inverse 버전이라고 볼 수 있습니다.
https://visionaisuite.net/blog/the-difference-between-computer-vision-and-human-vision
The Difference Between Computer Vision and Human Vision - visionAI
Computer vision might share a lot of similarities with human vision, but there are vastly significant differences between the two.
visionaisuite.net
(사람의 시각과 컴퓨터 비전의 차이점)
컴퓨터 비전은 왜 중요할까?
AI는 사람의 지능을 컴퓨터 시스템으로 구현하는 것입니다.
이때 컴퓨터 비전은 시각 지각 능력(Visual perception & Intelligence)이기에 AI에서 중요한 기술이라고 볼 수 있습니다.
즉, 컴퓨터에게 세상을 바라보는 눈을 만들어주는 것입니다.
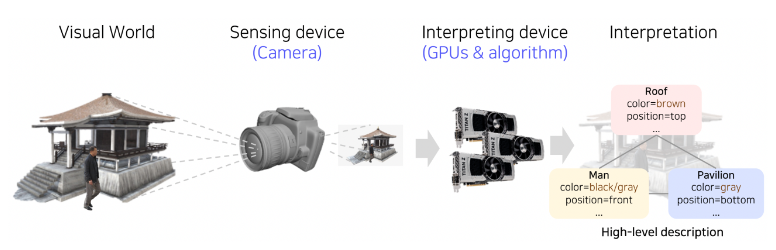
컴퓨터 관점에서 세상을 바라보기 위해서 카메라를 통해 장면을 찍어 영상을 만듭니다.
이를 GPU에 올려서 연산하면 장면에 대한 분석이 출력됩니다.
이를 다시 이용해 장면에 해당하는 3D씬을 재구성할 때 Computer Graphics(Rendering technic)라고 부릅니다.
과거의 머신 러닝의 패러다임은 Input -> Feature extraction -> Classification -> Output 으로 이루어졌습니다.
현재는 딥러닝 방법론을 통해 End-to-end로 구현이 훨씬 편리해지면서도 성능까지 높아졌습니다.
'Feature extraction + Classification' 이 부분을 직접 해주는 것이지요.
2. Image Classification
Classifier는 입력 이미지에서 어떤 물체가 영상 속에 들어있는지, 특정 클래스로 분류하는 분류기입니다.
이때 Nearest Neighbors(K-NN)를 통해 쿼리 데이터 근방에 포진하고 있는 이웃 데이터를 찾고, 데이터가 갖고 있는 라벨 정보를 통해 이미지를 분류합니다. 하지만 K-NN을 사용하기에 모든 데이터를 담기에는 한계가 존재합니다.
따라서 Neural Networks는 이러한 방대한 데이터의 복잡도를 압축하여 주입한다고 이해할 수 있습니다.
이때 Single-layer Neural Network 구조는 두 가지 문제점이 있습니다.
1) 클래스의 평균 이미지와 동떨어져있는 경우 잘 표현되지 않는 것, 2) Test time에서의 성능이 매우 떨어질 수 있다는 문제점입니다.
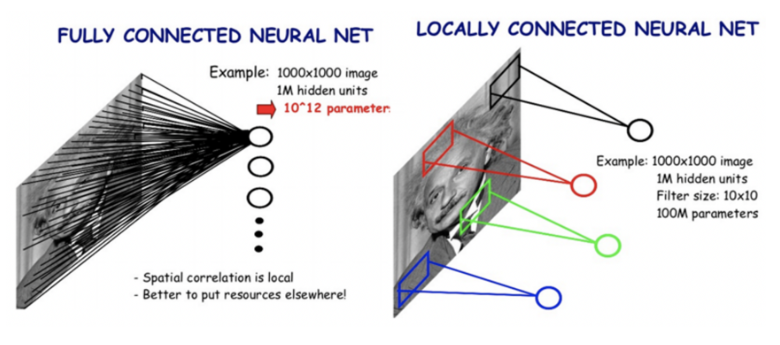
이러한 문제를 해결하고자 합성곱신경망CNN(Convolutional Neural Network)가 등장했습니다.
CNN은 완전연결신경망(Fully Connected Layer)가 아닌 Locally Connected Layer를 바탕으로 구성됩니다.
CNN 기반의 Image Classification은 다음과 같이 발전해왔습니다.
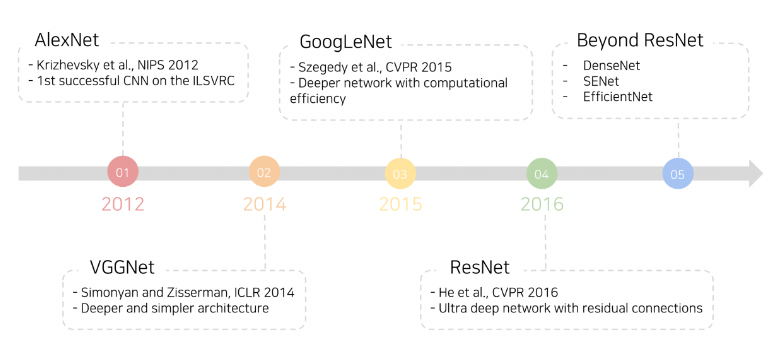
| AlexNet | ImageNet 스케일에서 동작하는 가장 간단한 구조 | 계산이 간단하지만, 용량이 매우 크고, 성능이 비교적 낮다 |
| VGGNet | 간단한 3x3 convolution을 기반으로 하고 있다. | 비교적 최근에 등장한 모델과 비교하면 모델 사이즈가 가장 크기에, 계산량 또한 부담이 크다. |
| GoogLeNet | Inception 계열 모델로 inception module과 auxiliary classifier를 사용한다. | ResNet보다 높은 성능을 보이지만 EfficientMet에 비해서는 낮은 성능을 보인다. |
| ResNet | depth scaling을 통해 깊은 네트워크 구조를 가진다. | 뛰어난 성능을 달성했지만, Inception 계열에 비해서는 무겁고, 계산량이 많으며 성능 또한 더 낮았다. |
일반적으로는 VGGNet 혹은 ResNet을 다양한 분류 구현의 backbone으로 많이 사용한다고 합니다.
다음으로는 데이터 부족 문제를 완화하는 Data Augmentation과 Annotation Efficient Learning에 대해 알아보겠습니다.
감사합니다.
'AI > Study' 카테고리의 다른 글
| [Study] <컴퓨터 비전의 모든 것> 공부하기(Annotation Efficient Learning) -3 (2) | 2024.06.10 |
|---|---|
| [Study] <컴퓨터 비전의 모든 것> 공부하기(Data Augmentation) -2 (0) | 2024.06.05 |
| [Seminar] 3D공간에서 인간을 이해하기 (0) | 2024.04.01 |


