안녕하세요. 정글러입니다.
오늘은 Data Augmentation에 대해 알아보겠습니다.
뉴럴네트워크는 컴퓨터만 이해할 수 있는 지식의 형태로 압축하는 모델입니다.
하지만 실제 세상에 존재하는 데이터는 학습된 데이터와 상당히 다릅니다.
이때 샘플 데이터와 실제 데이터의 갭을 매울 수 있는 방법이 data Augmentation이라고 볼 수 있습니다.
학습 데이터와 실제 데이터 사이의 간격을 좁히기 위해서 Crop, Shear, Brightness, Perspective, Rotate 등으로 영상 변환을 줍니다.
이는 OpenCV 등의 라이브러리에 사용하기 쉽게 구현되어 있습니다.
예시를 통해 살펴보겠습니다.
1) Brightness

밝기의 경우 RGB값에 상수를 더하거나 곱해줍니다.
다만 RGB값은 0부터 255이므로 값을 제한해줘야 합니다.
2) Rotate/ Flip

3) Crop

4) Shear
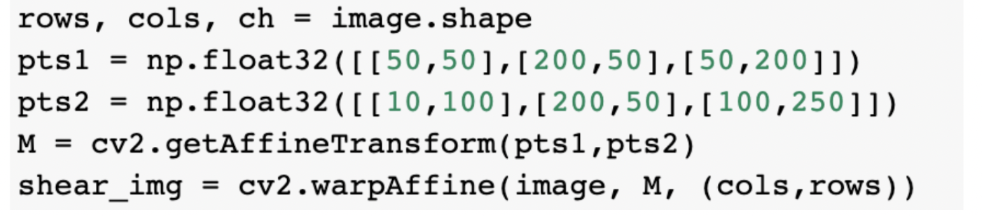
Affine transformation (shear)의 경우, 변환 전후에도 도형의 선과 평행 관계가 유지되며, 길이의 비율이 일정하게 유지됩니다.
이때 세 개의 변환 전후 대응쌍을 설정하여 변환행렬을 계산하고, 변환행렬을 기반으로 OpenCV 라이브러리를 활용하여
이미지에 affine transformation을 적용시킬 수 있습니다.
이렇게 다양한 Data Augmentation 방법이 있는데요, 이는 다양하게 조합하여 사용할 수 있습니다.
그러면 어떤 조합의 기법이 가장 좋은 성능을 보여줄 수 있을까요?
이러한 결정을 RandAugment 방법을 사용하여 자동으로 어떤 조합(policy)이 가장 좋을지 탐색할 수 있습니다.
즉, 사용가능한 data augmentation 옵션들을 입력해주었을 때,
그 리스트에서 랜덤으로 샘플링하여 적용하고 성능을 평가하는 방식으로 동작합니다.
*부스트캠프 <컴퓨터 비전의 모든 것>에서 공부한 것을 정리하였습니다.
감사합니다.
'AI > Study' 카테고리의 다른 글
| [Study] <컴퓨터 비전의 모든 것> 공부하기(Annotation Efficient Learning) -3 (2) | 2024.06.10 |
|---|---|
| [Study] <컴퓨터 비전의 모든 것> 공부하기 -1 (0) | 2024.05.17 |
| [Seminar] 3D공간에서 인간을 이해하기 (0) | 2024.04.01 |


