안녕하세요. 정글러입니다.
오늘도 부스트캠프의 <컴퓨터 비전의 모든 것> 공부를 이어가보도록 하겠습니다.
1. Transfer Learning
먼저 Transfer Learning은 데이터를 적게 쓰고도 좋은 성능을 발휘하기 위해 이전에 학습된 데이터를 활용하는 방법입니다. 한 데이터셋에서 배운 지식을 다른 데이터셋에서 사용 가능한 것이죠.
Transfer Learning에는 여러가지 방식이 있습니다.
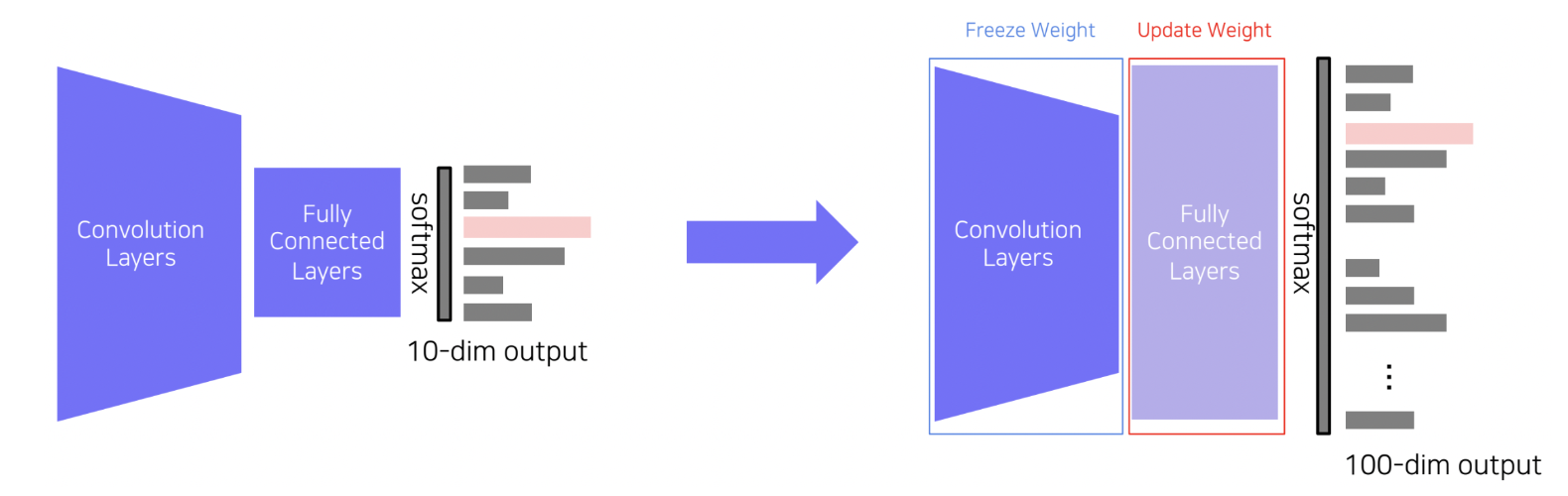
첫번째는 사전 학습된 모델에서 마지막 FC layer만 떼어내고, 새로운 FC layer로 교체하여,
새로 교체한 FC layer의 가중치만 업데이트하는 방식입니다. 적은 파라미터만 학습시키면 되기 때문에 비교적 좋은 성능을 기대할 수 있습니다.
두번째도 우선 FC layer를 교체해주는 것은 같습니다. 하지만 Convolution layer의 가중치 또한 업데이트를 진행합니다.
다만, Convolution layer의 learning rate를 작은 값으로 설정하여 학습을 진행합니다.
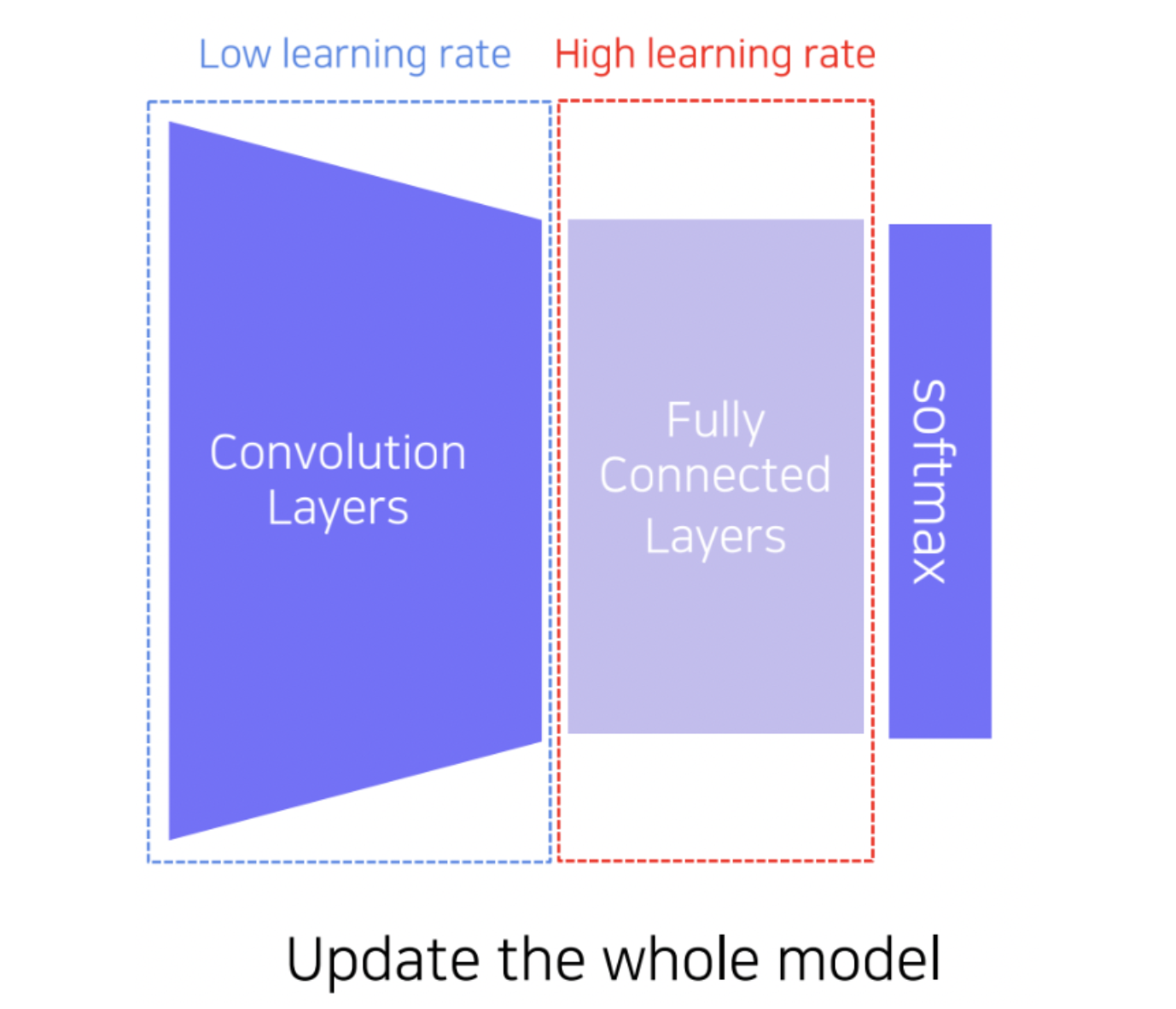
첫번째 방식은 데이터 사이즈가 아주 작을 때 사용하고, 그보다 데이터가 더 크면 두번째 방식을 활용하는 것이 좋습니다.
2. Knowledge Distillation
Knowledge Distillation은 이미 학습된 teacher network를 활용하여 Student model을 학습시키는 방법입니다.
최근에는, 레이블링되지 않은 데이터셋에 pseudo-lableling(가짜 레이블링)을 적용하기 위한 목적으로도 활용되고 있습니다.
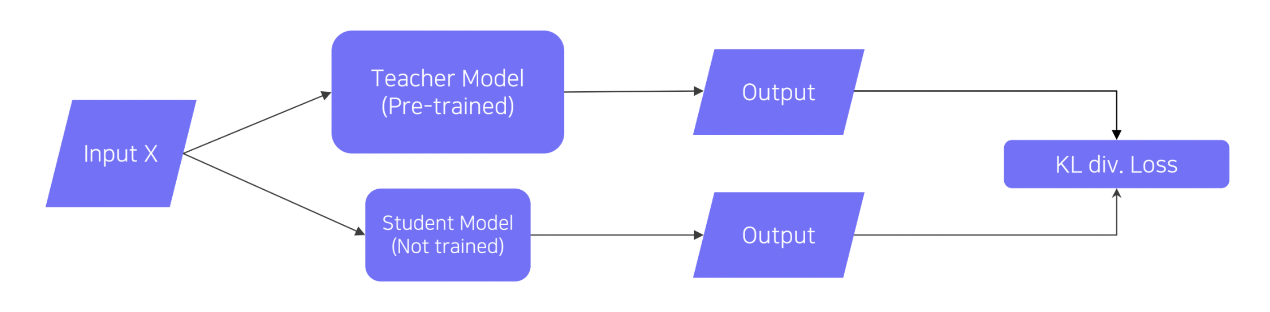
입력X에 대해 Teacher model과 Student model의 출력을 바탕으로 KL divergence loss를 계산하여 Student model을 학습시킵니다.
KL divergence loss는 두 출력 간의 distribution이 비슷하게 만들어지므로, Student model이 Techer model의 행동을 모방하도록 시키는 방식입니다.
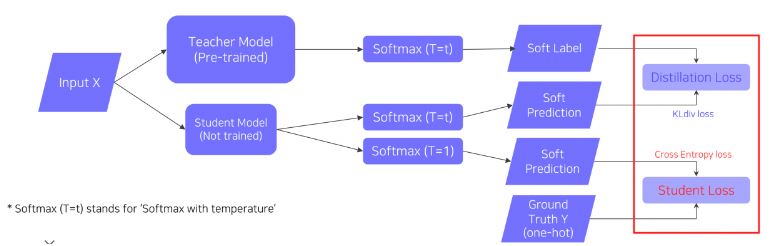
이는 레이블링된 데이터를 가지고 있을 때 True label을 고려하도록 설계한 것입니다.
여기서는 두 가지 Loss를 사용합니다. 1) KL div.를 계산하는 Distillation Loss, 2) Ground truth와 Student model의 출력을 바탕으로 Cross-entropy loss를 계산하는 Student Loss 입니다.
이 두 Loss의 가중합을 최종적인 Loss값으로 사용합니다.
3. Leveraging Unlabeled Dataset for Training
Semi-supervised Learning은 레이블링되지 않은 데이터를 학습에 활용하는 방법입니다.
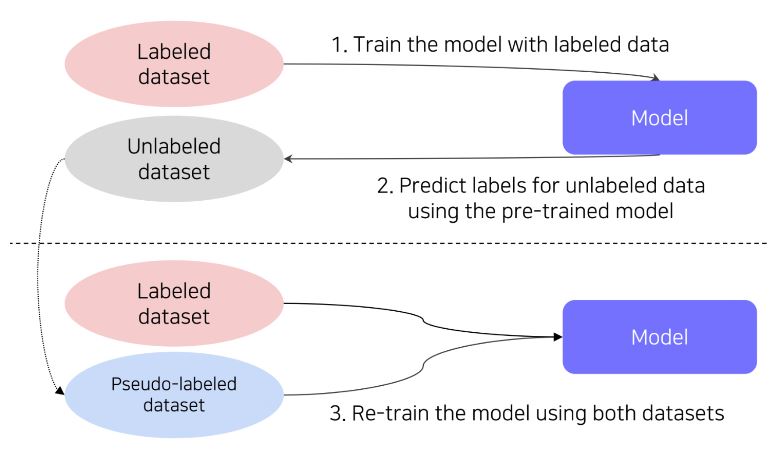
레이블링된 데이터를 활용하여 모델을 학습하고, 레이블링되지 않은 데이터에 대해 학습된 모델을 활용하여 레이블을 예측합니다. (pseudo-labeling). 이후 pseudo-labeled 데이터셋과 레이블링된 데이터를 합하여 보다 큰 사이즈의 데이터셋으로 새롭게 모델을 학습시킵니다.
Self-training은 최근 가장 성능이 좋았던 연구 방법입니다. (CVPR 2020)
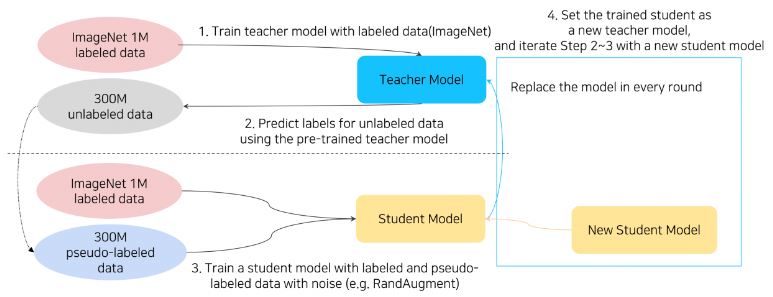
Semi-supervised Learning에서 학습된 Student Model을 다시 Teacher model로 대체하여, pseudo-labeling을 수행하고 새로운 student model을 학습시키는 과정을 2-4번 반복하는 것입니다.
이때 Knowledge Distillation에서는 Student model의 사이즈가 Teacher model 사이즈보다 작은데, Self-training에서는 반대로 student model 사이즈를 더 크게 설정한다는 것이 차이점 입니다.
감사합니다.
'AI > Study' 카테고리의 다른 글
| [Study] <컴퓨터 비전의 모든 것> 공부하기(Data Augmentation) -2 (0) | 2024.06.05 |
|---|---|
| [Study] <컴퓨터 비전의 모든 것> 공부하기 -1 (0) | 2024.05.17 |
| [Seminar] 3D공간에서 인간을 이해하기 (0) | 2024.04.01 |


