안녕하세요. 정글러입니다.
오늘은 세미나 'Understanding Humans in the 3D Space'를 정리해보고자 합니다.
유튜브에 업로드된 영상을 요약하고자 하는데, 문제가 되면 삭제하겠습니다!
https://www.youtube.com/watch?v=Nirr3OC_k54&t=1275s
1. Intro
해당 강의는 메타의 문경식님이 진행해주셨습니다.
연구의 목표는 사람과 사람, 사람과 사물의 인터랙션을 3D환경에서 모델링하고, 인식하는 것입니다.
Can we have interactions in virtual space indistinguishable from reality with Als?
AI를 통해서 버추얼 스페이스에서 현실화가 불가능한 인터랙션을 어떻게 구현할 수 있을까?
먼저 소개해주신 Photorealistic Telepresence의 경우,
3D 아바타가 사람같이 움직이면서 인터랙션하는 Telepresence를 구현하는 것을 목표로 하고 있습니다.
두번째는 Interactable Virtual Agents입니다.
이는 피지컬 제한없이 렌더링된 버추얼 에이전트에게 리얼 피드백을 받으며 골프를 배울 수 있습니다.
이를 위해 필요한 기술은 다음과 같습니다.
1) Authentic 3D avatar
2) Human motion synthesis
3) 3D pose estimation
이러한 기술은 학술과 산업 부문 모두에서 계속해서 주목하고 있는 부분입니다.
2. Challenge
우선 인간의 신체가 아주 복잡하다는 챌린지가 있습니다.
휴먼 모션을 캡처하기 위한 파이프라인은 100개의 카메라를 설치하는 것입니다.
하지만 이는 특수한 스튜디오에선 가능하지만, 일상생활에선 불가능하다는 이슈가 있습니다.
1) Occlusion ambiguity
2) Scale ambiguity
3) depth ambiguity
3. How to address the challenges?
강사분께서 주목한 것은 latent space입니다.
latent space는 prior distribution을 나타냅니다.
해당 distribution을 알고 있으면 3D human을 랜덤하게 샘플링, generate 할 수 있다는 특징을 갖습니다.
synthesize, generate, animate, interact가 가능해지는 것입니다.
이를 위해선 body pose estimation이나 clothed human이나 motion synthesis를 연구해야 한다고 합니다.
여기서 문경식 강사님은 손에 주목했습니다.
손은 감정을 표현하거나 사물과 인터랙션할 때 아주 중요하게 사용되기 때문입니다.
4. Two Interacting Hands
그 중에서도 두 개의 손이 상호작용하는 과정을 집중했는데요,
Semi-Automatic Annotation으로 manual과 automatic이 합쳐진 annotation 파이프라인을 사용했습니다.
- Trained a strong 2D keypoint detector on our human-annotated set
- Tested on all remaining images and 3D coordinates are abtained from triangulation with RANSAC
- 2.78mm error on held-out human annotated evaluation set
4.1) Encoders
인코더에서 중요한 것은 다양한 in-the-wild image를 robust해야합니다.
MoCap datasets과 In-the-wild datasets을 인코더할 때, mocap datasets은 3d data가 있다는 점이 장점이고,
In-the-wild datasets은 3d data는 없지만, 다양한 이미지가 있다는 점이 장점입니다.
4.2) Decoders
latent space에서 3d human을 recover하는 역할을 맡습니다.
여기서 중요한 것은 가능한 모든 3D human 스페이스를 span해야 한다는 것입니다.
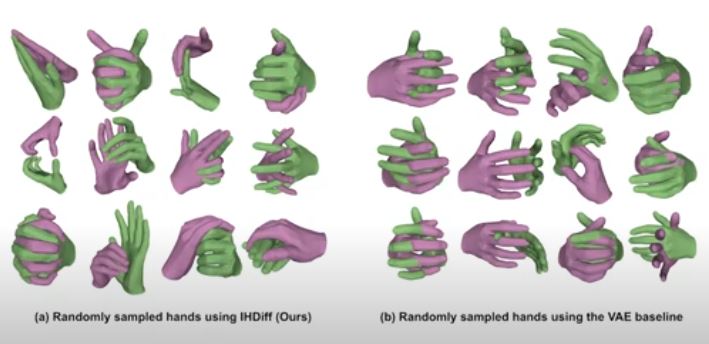
a) Random sampling
b) Conditional random sampling
c) Fitting to observations
5. Outro
https://youtu.be/Kx_nVrEKwTE?si=Gx2-48T-tacZhsTj
메타에서 하는 EMG 영상입니다.
EMG는 뇌에서 오는 electric signal을 읽는 것입니다.
이러한 센서는 저조도 환경이나 모션 블러가 심할 때 해당 정보로 3D hand pose가 보강될 수 있다고 합니다.
여러 센서를 융합하는 것이 중요하다고 봅니다.
3D 환경에서 어떠한 기술적 배경이 뒷받침 되어야 하는지 궁금했었는데
이렇게 손을 모델링하는 것만으로도 많은 연구가 이뤄지고 있는 것이 재밌었습니다.
real-time에서 손이 굉장히 복잡하고 사실적으로 보여주는 것이 얼마나 중요한지 깨닫게 되었습니다.
실제로 예전에 VR영화에서 제 손을 볼 때도, 손이 어색하면 몰입감이 떨어지더라고요.
섬세한 손의 움직임을 구현해내기 위해서 필요한 기술에 대해 알아보는 시간이었습니다.
감사합니다.
'AI > Study' 카테고리의 다른 글
| [Study] <컴퓨터 비전의 모든 것> 공부하기(Annotation Efficient Learning) -3 (2) | 2024.06.10 |
|---|---|
| [Study] <컴퓨터 비전의 모든 것> 공부하기(Data Augmentation) -2 (0) | 2024.06.05 |
| [Study] <컴퓨터 비전의 모든 것> 공부하기 -1 (0) | 2024.05.17 |


