안녕하세요. 정글러입니다.
Semantic Segmentation에 대해 알아보겠습니다.
이는 이미지 분류를 픽셀 단위로 분류하는 task입니다.
1. Fully Convolutional Networks (FCN)
입력부터 출력까지 학습가능한 구조입니다.
입력 이미지의 해상도와 상관없이 동작할 수 있어 호환성이 높은 구조 입니다.

Fully connected layer은 Convolutional layer에서 출력된 feature map을 flattening하여 입력으로 사용했습니다.
이는 이미지의 공간 정보를 고려하지 못합니다.
이를 해결하기 위해 각 픽셀 위치마다 채널 축으로 flattening하여 각 위치에 해당하는 벡터를 구해줍니다.
1x1 convolution으로 이러한 연산을 수행합니다.
하지만 넓은 receptive field를 확보하기 위해 pooling을 진행할수록 저해상도의 출력을 얻게 되는 문제가 발생할 수 있습니다.
이러한 저해상도 문제를 해결하기 위해서 Upsampling 방법을 사용하게 됩니다.

Upsampling의 방법은 두 가지가 있습니다.
Transposed convolution과 Upsample and convolution입니다.
1)Transposed convolution

중첩되는 부분에 Checkerboard artifact 이슈를 막기 위해 Stride와 Filter 사이즈를 설정해주어야 합니다.
2) Upsample and convolution

전체 upsampling 과정을 두 단계로 분리하여,
먼저 Nearest-neighbor, Bilinear interpolation 등의 interpolation 과정을 통해 upsample시키고,
다음으로 학습가능한 형태를 더해주기 위해 이를 convolution layer를 통과시키는 방법입니다.
2. Hypercolumns for object Segmentation

Hypercolumn은 FCN과 유사한 아이디어 기반의 모델입니다.
낮은 레이어의 특징과 높은 레이어의 특징의 결합을 강조하고 있다는 점에서 차이가 있습니다.
또, 별도의 알고리즘을 사용하여 얻은 물체의 bounding box의 입력으로 사용한다는 점에서도 다릅니다.
3. U-Net
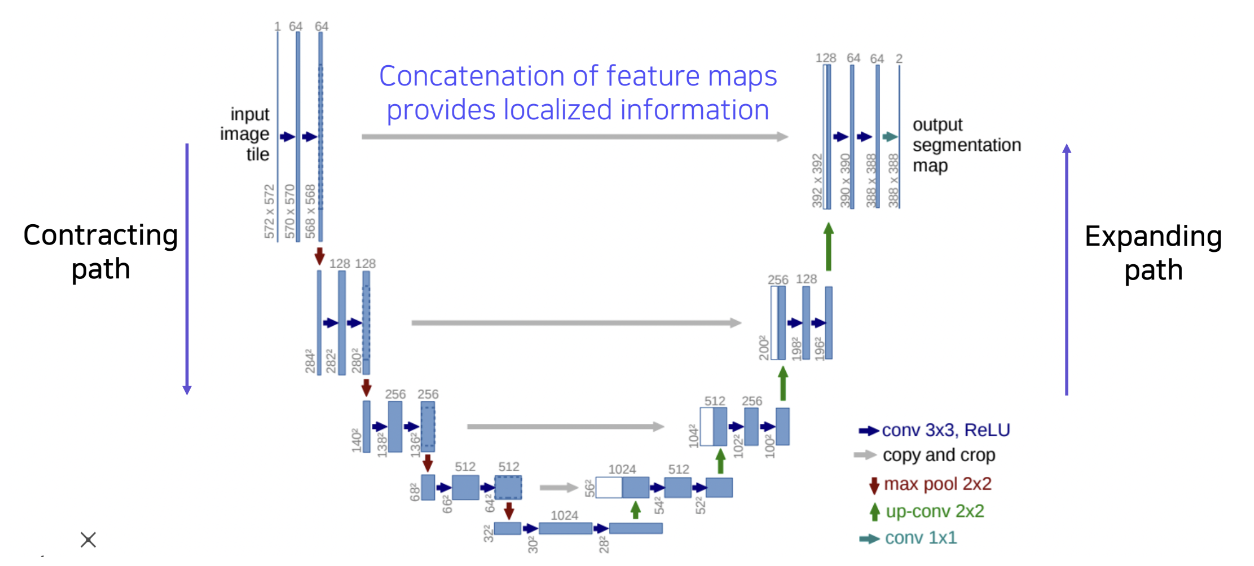
Downsampling 과정에서는 pooling을 통해 공간해상도를 절반으로 줄이고, 채널 수를 두배로 늘리는 방식으로 feature map을 얻고 있으며, upsampling 과정에서는 반대로 공간해상도를 두배로 늘리고, 채널 수는 절반으로 줄이는 방식으로 segmentation map을 얻고 있습니다.
| Downsampling | Upsampling |
| - Halve the size of the feature map - Double the channel of the feature map | - Double the size of the feature map - Halve the channel of the feature map |
그리고 각 과정에서 대칭적으로 대응하는 부분을 보면, skip connection을 통해 지역적인 정보를 담고있는
downsampling 과정에서의 feature map을 upsampling 과정의 segmentation map에 concatenation 해줍니다.
4. DeepLab
DeepLab v3+에서는 semantic segmentation의 입력 해상도가 워낙 크기 때문에 연산이 복잡해지는 것을 완화하기 위해
dilated convolution을 depthwise separable convolution과 결합하여 사용합니다.
1) CRF는 픽셀과 픽셀 사이의 관계를 이어주고, 픽셀맵의 그래프를 통해서 경계를 잘 찾을 수 있도록 모델링을 한 것입니다.
출력한 경계선을 활용해서 score map이 경계선에 맞아떨어지도록 확산시켜줍니다.

2) Dilated convolution은 convolution filter들 사이에 dilation factor 만큼 space를 넣어주는 방법입니다.
이를 통해 실제 convolution filter보다 넓은 영역을 고려할 수 있는, 즉 지수적으로 receptive field를 확장할 수 있는 방법입니다.

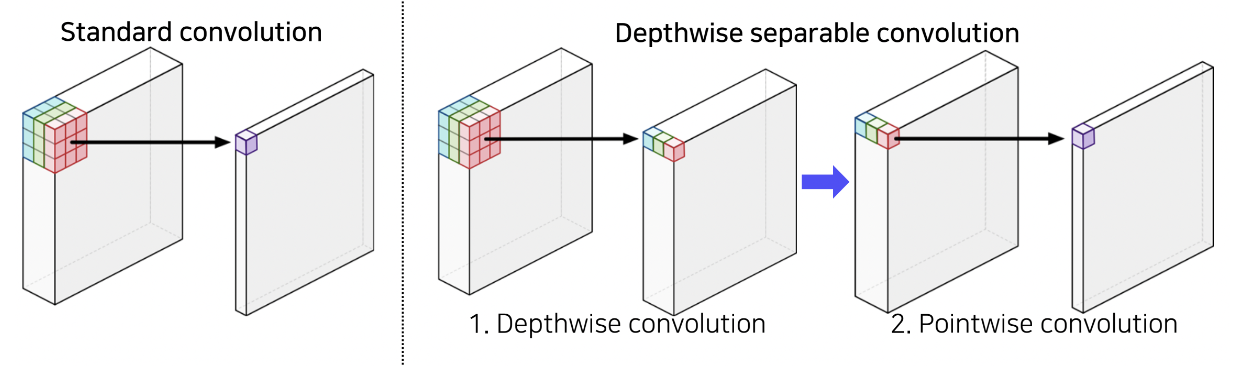
3) Depthwise separable convolution
Standard convolution의 경우 하나의 출력 픽셀에 대한 activation을 얻기 위해 전체 필터 사이즈의 크기를 채널 축으로 내적하는 과정을 거칩니다. 반면 Depth-wise convolution은 이 절차를 두 개의 과정으로 나눕니다.
먼저 각 채널 축으로 convolution을 수행하여 각 채널에 대한 값을 추출하고,
이를 point-wise convoltuion, 즉 1x1 convolution을 통해 하나의 activation으로 추출합니다.
이러한 방식을 사용하게 되면, convolution의 표현력도 유지할 수 있으면서, 연산량을 크게 줄일 수 있게 됩니다.

먼저 dilated convolution을 적용하며, 일반적인 convoltuion 보다 큰 receptive field를 가지는 convoltution을 수행해줍니다.
또한 영역 별로 주변 물체와의 거리, 연관된 정보들이 서로 다르기 때문에 multi-scale을 다룰 수 있도록 spatial pyramid pooling을 수행해줍니다.
이렇게 얻은 feature map들을 concatenation한 이후에 1x1 convolution을 적용하여 하나로 합쳐줍니다.
그 이후에는 Decoder 단에서 낮은 레이어의 feature map과 pyramid pooling을 거친 feature map을 concatenation 시켜줍니다.
이를 upsampling하여 최종적인 segmenation map을 출력하는 구조입니다.
감사합니다.
'AI > Study' 카테고리의 다른 글
| [Study] <모두를 위한 파이썬 (PY4E)> 후기 (4) | 2024.09.02 |
|---|---|
| [Study] <컴퓨터 비전의 모든 것> 공부하기(Annotation Efficient Learning) -3 (2) | 2024.06.10 |
| [Study] <컴퓨터 비전의 모든 것> 공부하기(Data Augmentation) -2 (0) | 2024.06.05 |
| [Study] <컴퓨터 비전의 모든 것> 공부하기 -1 (1) | 2024.05.17 |
| [Seminar] 3D공간에서 인간을 이해하기 (0) | 2024.04.01 |



